
路径名解析功能分析
路径名解析就是依次寻找目录中的元素,直到找到匹配的文件。比如要想寻找/a/b.txt文件,则解析顺序如下:
- 在根目录’/‘inode中寻找名为a的条目。
- 由于a也是一个目录,则继续在a的inode中寻找名为b.txt的条目。
- 如果找到则返回b.txt的inode。
1. skipelem函数
path表示文件的路径名,类似于"/a/b.txt"这样的,name用于保存解析出的第一个元素的名字,对于"/a/b.txt"而言,解析出的第一个元素就是a。skipelem返回的是除去第一个元素后的路径名。

- 首先跳过所有的'/'字符。
- s表示第一个既不是'/'也不是'\0'的字符的位置。
- 接着寻找下一个为'/'或者'\0'的字符的位置,用path表示。
- 然后将s代表的字符复制到name中,表示解析出的第一个元素。
- 接着跳过path中的所有'/'字符,之后path就表示除去第一个元素后的路径名。
2. namex函数
namex就是解析路径名的核心函数,此函数会被namei和nameiparent调用。nameiparent参数用于标明最后返回的是路径名的inode还是路径名上一层元素的Inode。
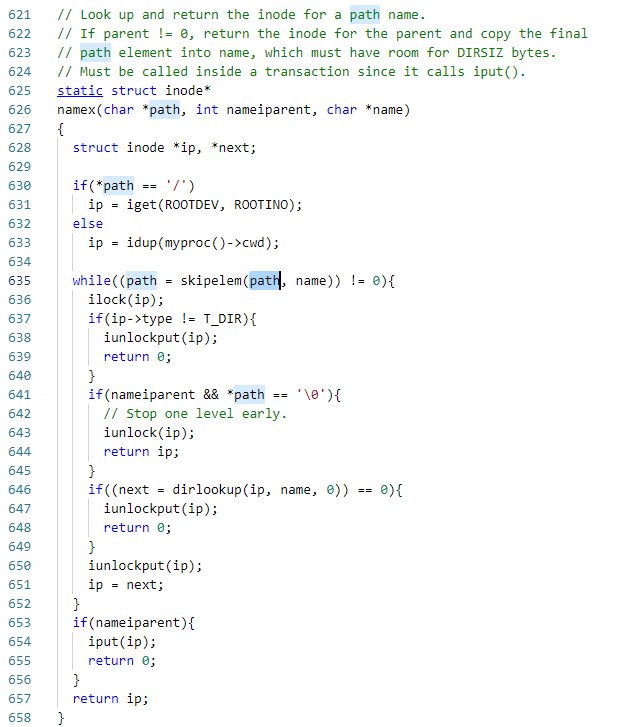
- 首先检查路径名是全路径名还是相对路径名,如果是全路径名则调用iget获取根目录的inode,如果是相对路径则通过调用idup获取当前工作目录的inode。
- 接着通过while循环调用skipelem循环解析路径名。
- 在while循环的开始首先调用ilock锁住Inode,接着检查inode的类型,如果不是目录类型直接返回。然后检查调用者是否想返回的是路径名上一层的inode,判断条件是nameiparent为1并且path地址中的值为0。
- 然后根据解析的名字调用dirlookup来在目录中寻找其对应条目并返回inode,由此可以看出,ip表示的是上一层目录的inode,而next表示的是当前name对应的Inode。
- 如果找到则返回,如果没有则继续下一轮解析查找。
- 如果while循环结束且nameiparent为1,则表示返回上一级目录失败,因为如果上一级目录存在,在while循环中就会返回。
- 最后返回路径名对应的Inode。
3. namei和nameiparent
这两个函数分别用于根据路径名返回对应的inode和上一级inode,函数很简单,就是对namex做了一层封装。

评论